
How to use RL to teach vision models effective reasoning.
Now, vision models are soaring…


LLMs sucked at reasoning for too long, vomiting out bad quality outputs. Then DeepSeek blew up in the media last year, using RL to teach LLMs to reason better.
Before DeepSeek came out, so many people were working on reasoning techniques like Chain-of-Thought reasoning to improve the reasoning ability of LLMs, and while they were quite similar to DeepSeek, they lacked the RL basis that made DeepSeek so effective.
Given this, can we see a similar spike in performance by incorporating RL into vision-language models?
Although DeepSeek is good at reasoning, we still don’t have a model that’s that good at visual reasoning. Ever since DeepSeek came out, the possibilities for what we can achieve are endless.
In this blog, we’ll look at this problem of visual reasoning in more detail, explore how it was approached without RL, and see how it can be tackled with RL, unlocking huge untapped research potential.
Improving visual reasoning without RL
What do we mean by visual reasoning?
Visual reasoning is the ability to accurately answer questions involving difficult reasoning AND an image.
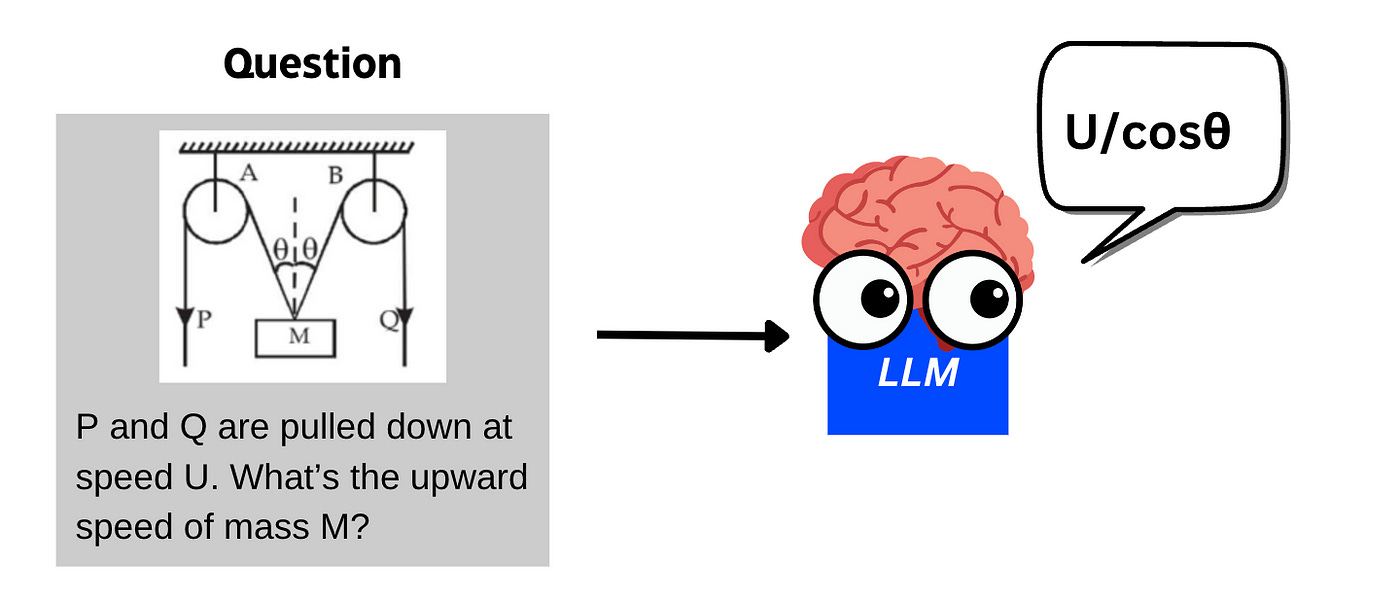
The goal is to get vision-language models to reason and think before they answer a question related to an image.
You might ask the LLM to follow a step-by-step approach to reasoning like this:
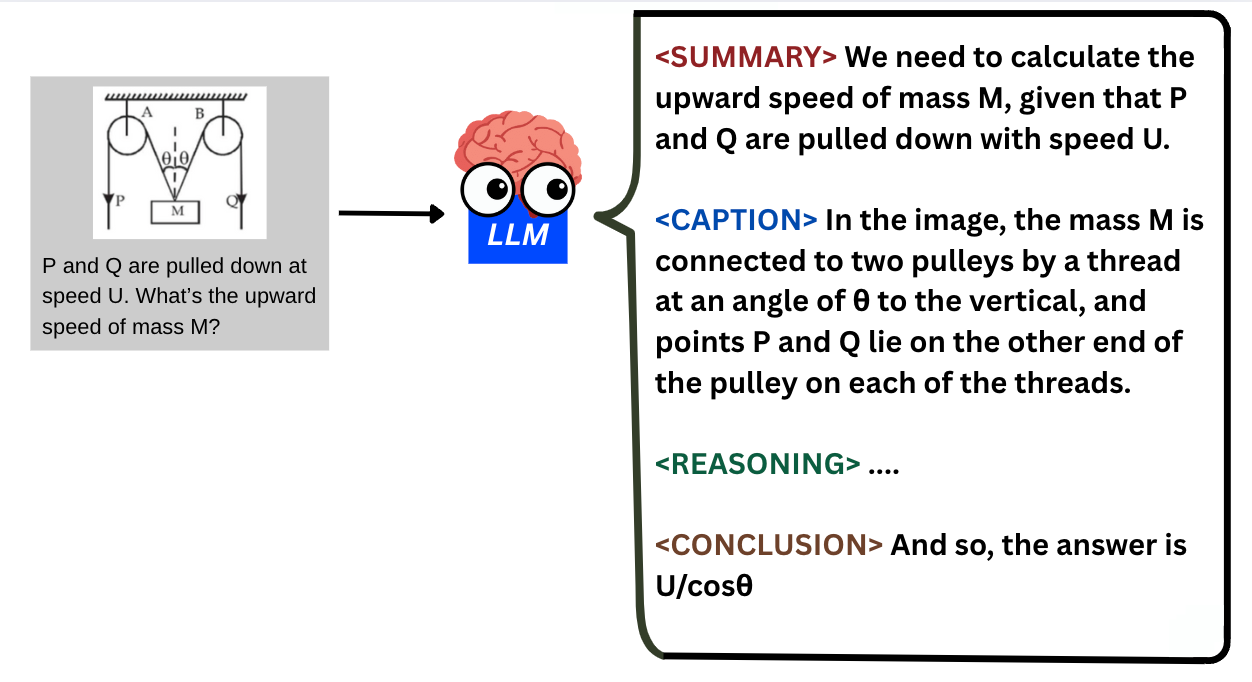
Summary: The model summarises the task.
Caption: The model describes the image in words.
Reasoning: The model “thinks” and gives analyses to help it answer the question.
Conclusion: The model finally answers the question.

This is called a Chain-of-Thought (CoT) process, since the model is forced to think in steps before arriving at an answer. By doing that, the model reasons better, and more frequently arrives at the correct answer.
Essentially, the hope is to train our LLM to follow this precise process every time it’s given a question. Each stage in the process lies within the corresponding tags for that stage.
But how do we train the LLM to output responses like this? There are two ways you could do it.
1. Simply convert each prompt into a sequence of prompts to effect the Chain-of-Thought process.
This is the most obvious way of doing it. Let’s say we want LLaVA to get better at reasoning. In that case, we would convert a prompt into a sequence of prompts, encouraging the LLM to follow the steps and get to the answer.
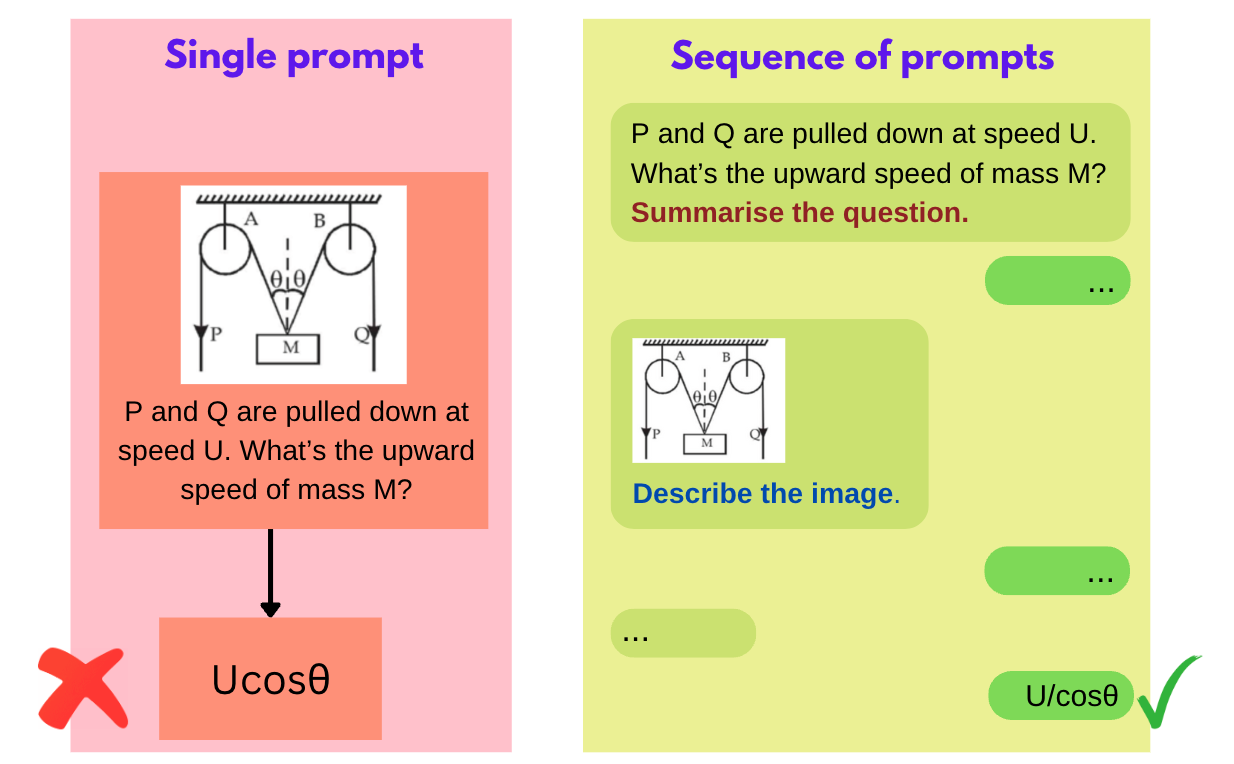
This method has a lot of advantages:
It’s simple and doesn’t require complex coding.
It’s efficient since we’re not doing any training.
But the major issue here: we’re not changing the capabilities of the model — only changing the way we prompt it to bring out its capabilities more.
Can we somehow change the LLM’s capabilities instead?
2. Perform supervised finetuning to train the LLM to think in Chain-of-Thought
What if we want to change the inherent nature of the LLM without altering the prompting style?
We can do this by supervised finetuning.
Suppose we take a dataset of image-question-answer triplets. One data point will look like this:

Now, the goal is to train the LLM to automatically answer in the step-by-step format described previously.
In order to do this, we need to generate a dataset with answers in the precise format we expect. So we prompt GPT-4o using method 1, and generate summaries, captions, reasonings, and conclusions.
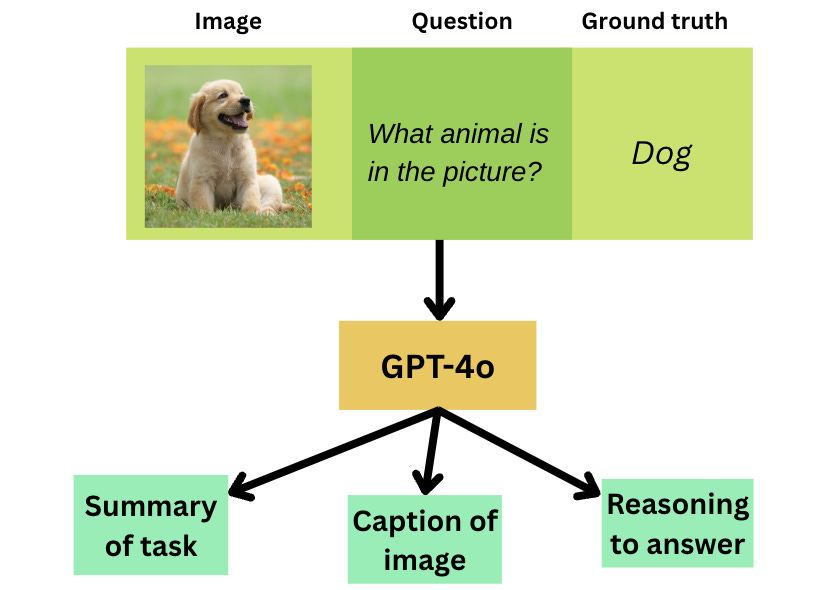
The way we would prompt GPT-4o to generate one of these pieces of information is illustrated below:

We then use our final datapoints with 6 pieces of information (image, question, ground truth, summary, caption, and reasoning) to finetune LLaVA, forcing the LLM to learn to answer image-related questions in this specific format.
Let’s call this final trained model LLaVA-o1, a vision-language model with the ability to reason while answering image-based questions.
Limitations
This approach was performed by a bunch of researchers to develop “LLaVA-o1” in November last year. But given the state of reasoning models now, there are some major limitations with this approach:
LLaVA-o1 will never surpass the performance of GPT-4o, since we are using AI-generated data from GPT-4o to train another AI. That really limits what we can do with this approach, since it relies on the existence of a better AI like GPT-4o in order for it to even be possible to create an LLM like LLaVA-o1.
Supervised finetuning (SFT) rarely generalises. SFT tends to memorise the data points given to it rather than generalising on the data. This means that in this case, finetuning it on a particular set of images might only improve performance on those images and none others. RL, on the other hand, tends to be more generalisable.
We are hardcoding the reasoning method into the LLM. We are telling the LLM exactly how to reason — to first provide a summary, then a caption, and so on. However, some questions might be best tackled with a different set of steps. This approach is like teaching students the exact reasoning procedure instead of letting them figure it out for themselves.
There are still some benefits of the method:
While LLaVA-o1 doesn’t surpass GPT-4o, it does surpass most other models of comparable size to LLaVA-o1, including GPT-4o-mini.
While hardcoding the reasoning method isn’t going to always work, it still improves performance significantly, proving that this specific reasoning procedure actually is sufficient in a large proportion of cases.
Improving visual reasoning with RL
After DeepSeek introduced their new RL method to train reasoning models, the advantages of this method over traditional methods became so much more clear.
We’ll first see how we can apply RL to improving the reasoning ability of vision-language models, and then explore how that approach works better than what we’ve already discussed.
Training the vision-language model with RL
For any training process, we need to define a problem we want the LLM to solve, and train using data corresponding to that problem.
We’ll go ahead with the image classification problem.
The image classification problem is simple — given an image, we want to assign it a label based on its visual content.
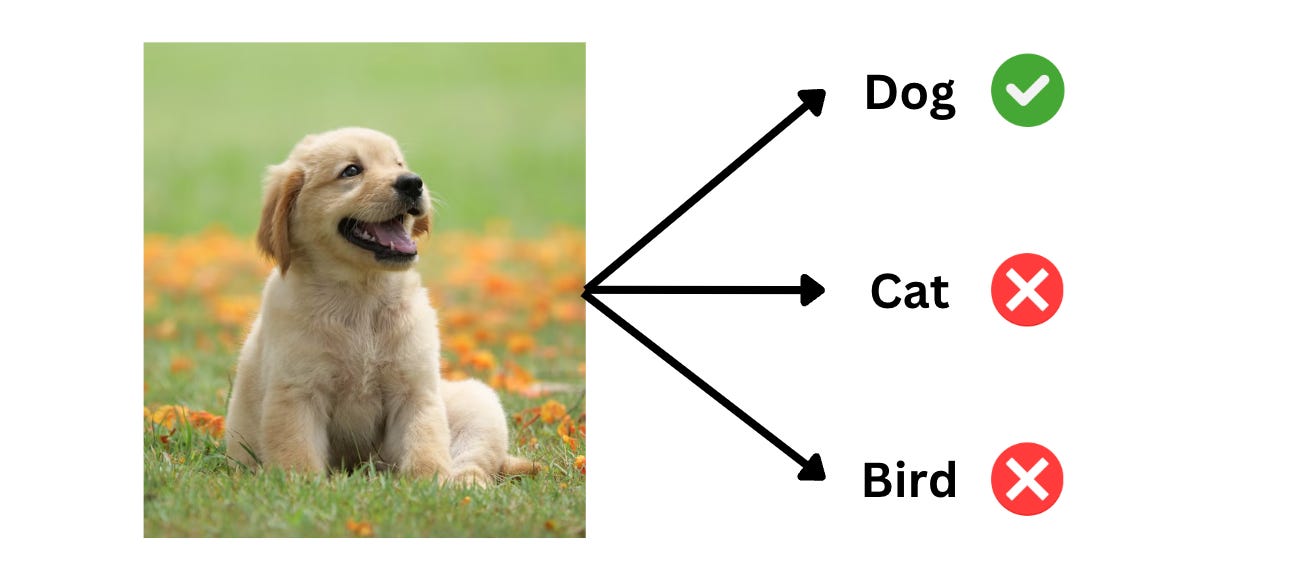
How does each data point look?
In our dataset, each data point contains three pieces of information: an image, a caption, and a question (whose answer is the caption).
The goal would then be to input the image and question into the LLM and expect the output of the LLM to match the caption as closely as possible.
Reward
There are typically two types of rewards in these RL training processes:
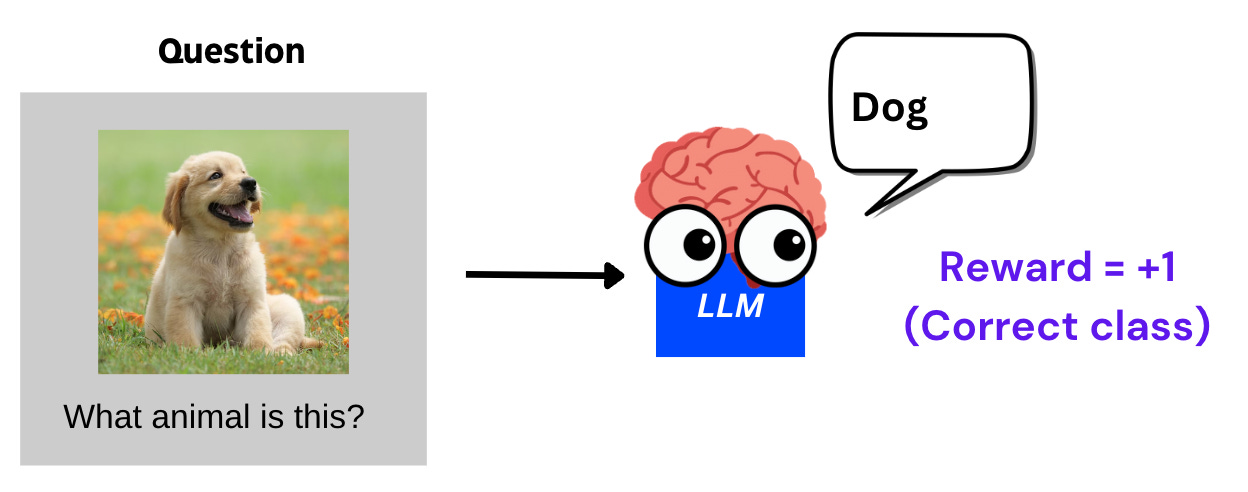
Correctness reward: If the LLM classifies the image correctly based on the question and outputs the correct answer (“dog” in the previous example), then a reward of +1 is provided.
Format reward: If the LLM outputs its thinking process within <think></think> tokens, and outputs its final answers within <answer></answer> tokens, then the LLM gets rewarded for sticking to the format. This encourages the LLM to “think” before answering, which is a crucial aspect of these RL training strategies.
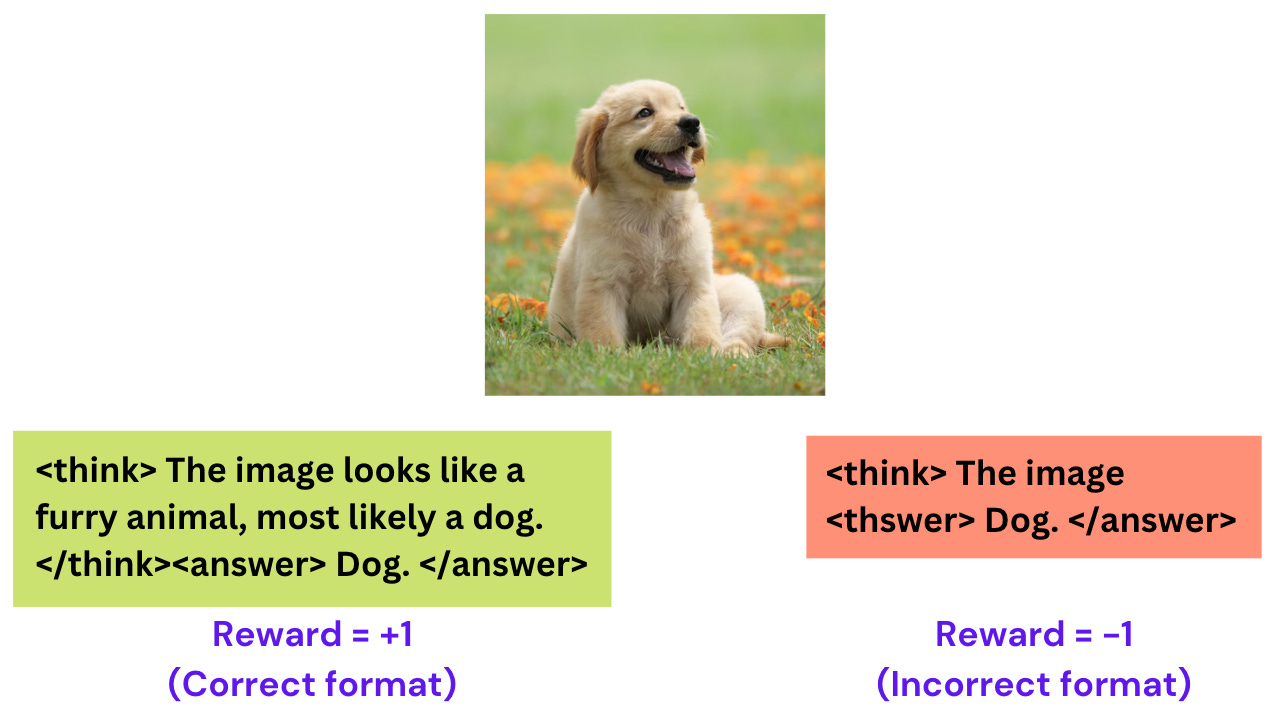
By enforcing thinking tokens, we ensure the LLM thinks clearly and considers multiple possibilities before blindly answering. This technique has shown promise in helping LLMs reason better and get to the right answer.
Training process
We use the above rewards to provide incentives to the LLM and we modify its weights through a training process, allowing the LLM to automatically change its behaviour to optimise for getting the correct answer.
This has already been shown to significantly improve reasoning ability in textual situations, and it could do the same for visual reasoning.
Advantages of this method
There are some key advantages of RL over the previous method:
We are no longer using unclean data from one AI to train another AI. Instead, we implement a reward function which acts as a clean signal to improve the AI’s performance. There are no theoretical limits to its performance and it isn’t limited by another AI’s performance.
RL generalises much better than SFT. This is because the LLM is simply learning using an objective reward function, figuring out behaviours that optimise the reward function. This leads to better generalisability.
We are not hardcoding a particular reasoning method into the LLM. That means it is not only capable of learning the reasoning approach on its own, but it also learns to determine the best reasoning method for any given problem, much like humans.
Conclusion
Over the course of this blog, we talked about how visual reasoning was achieved by researchers without RL, and how it can be achieved now with RL.
There’s a huge research opportunity in applying RL to solve problems like these, and improving generalisability and efficiency significantly.
Acknowledgements
The first approach, aiming to improve reasoning without RL, was done by this paper. The second approach hasn’t yet been implemented by anyone and I’m hoping to work on it myself. All diagrams in this blog were made by me in Canva.