
How Attention Shapes Understanding in LLMs
This explains why RAG is still so effective.


Since ChatGPT came out, everyone was talking about this new technique called Retrieval-Augmented Generation (RAG).
And even in 2026, it’s still one of the most effective techniques for LLM performance.
It worked well in preventing hallucinations and ensuring factually correct outputs by providing a context. Several people were trying to optimise the processes involved in RAG to ensure it works as well as possible. And any RAG optimisation experiment needs to start with understanding how RAG works in the first place.
But, what is RAG?
Retrieval-Augmented Generation (RAG)
RAG is a technique that’s made up of three stages:
Retrieval
Augmentation
Generation
During the Retrieval stage, the LLM makes use of the question to find the most similar paragraphs in a given document. For example, if the question asks “What is the most popular language in Chennai?”, the LLM will search for paragraphs in some document that refer to Chennai and the languages spoken there.
In the Augmentation stage, the LLM augments the retrieved paragraph to the query (the question). Now we might have a prompt of the format:
Context: Tamil is the language spoken by most of Chennai’s population; English is largely spoken by white-collar workers. As per the 2011 census, Tamil is the most spoken language with 3,640,389 (78.3%) of speakers…
Question: What is the most popular language spoken in Chennai?
In the Generation stage, the prompt is passed into the LLM (e.g., ChatGPT), which then generates the output.
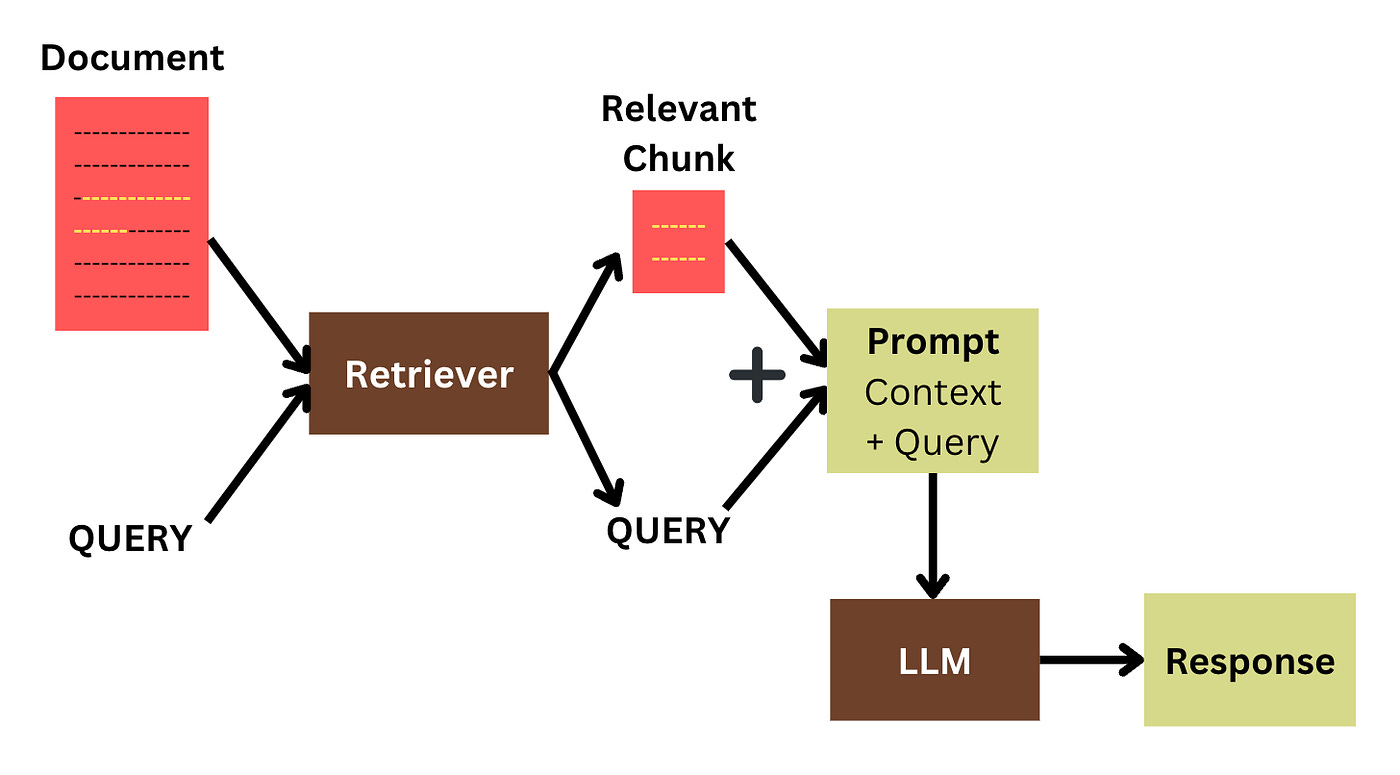
The Retrieval-Augmented Generation Process (simplified)
Let’s look at an example of this process.
Let’s say the user asks the LLM “What is the most popular language spoken in Chennai?” and the LLM incorrectly outputs “Hindi”.

